A Quick Start to AllenNLP for Natural Language Processing
If you are using AllenNLP for the first time, looking at the quick start guide can be overwhelming and there isn’t a guide for the multitude of NLP tasks out there. There are different tools out there to train a Natural Language Processing (NLP) model, with the two main ones being HuggingFace and AllenNLP. In this quick guide I will be covering how to start on an AllenNLP project using a Constituency Parser. At the point of writing this guide, AllenNLP is at version 2.9.3
Objectives
- To train a ML model using AllenNLP and its associated packages with minimal code
- Readers will hopefully be able to have a high level understanding of what is required to get started on AllenNLP
Why AllenNLP?
Majority of NLP models are built on PyTorch, what AllenNLP does is to abstract the steps of building a model in PyTorch from scratch, making it much easier and quicker to get started. This gives users the ability to quickly prototype and manage multiple experiments with different parameters.
Getting Started
Installing AllenNLP
Link to the installation guide for AllenNLP
It is recommended to install allennlp-models as there are many useful classes contained there. Some examples include parsers for: Constituency Parsing, Dependency Parsing, Semantic Role Labelling (SRL) and much more. At the point of writing this guide, AllenNLP has a quick start tutorial for Sentiment Analysis.
Overview of AllenNLP
The Hard Way
In this post I will aim to cover the easy method of using AllenNLP to train a model, therefore I will only go through this section briefly. For more information in this section, link to the resources can be found here.
AllenNLP consists of several components to get it working they include:
- DatasetReader
The DatasetReader is the entry point of how the data will be fed into the model. This section performs any preprocessing steps required to turn your input data into tensors. Depending on your task, you can find the associated DatasetReader under allennlp-models instead of manually creating one on your own.
- Model
The model specifies the architecture you will be using, for example a LSTM or Bi-LSTM encoder, or RNN with Linear layers. This can be customised to suit your experiments as required.
- Predictor
The predictor is used to perform inference on the trained model.
- Configuration File
This is one of the biggest features in AllenNLP. The configuration file lets you control the training and model parameters, allowing for quick customisation and readability for each parameter for tuning and publishing.
The Easy Way
The easy way involves using the classes in allennlp-models and only requires a configuration file. Depending on the NLP task you would like to work on, refer to this section for the respective NLP tasks.
Note: The example shown is for illustration, feel free to experiment with your own parameters
Setting up your configuration file:
- Defining the
dataset_reader
- Setting the dataset reader:
"dataset_reader":{
}
- Defining the reader type, to search for the specific reader, you will need to go to the repository for
allennlp-models / allennlp-models/ <folder name> / dataset_readersand retrieve the registered name highlighted in red. For the example shown for the constituency_parser we will be using thePennTreeBankConstituencySpanDatasetReader.
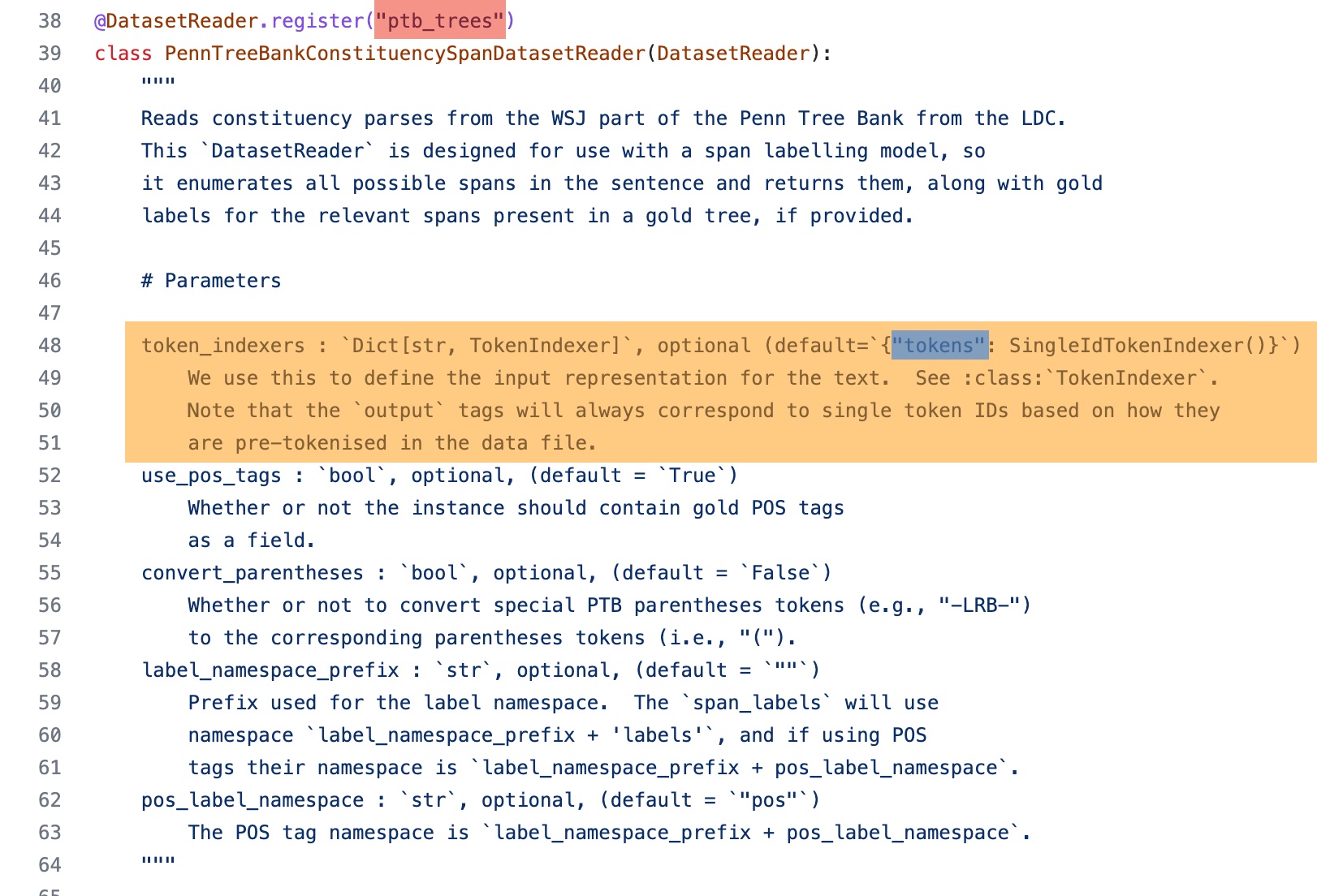
"dataset_reader":{
"type": "ptb_trees",
}
- Setting the parameters
With the similar idea above, for our use case we will want to define the token_indexers. In this example we will be using the TokenIndexer that requires a transformer which requires a model_name, the model_name can be obtained from HuggingFace (Note that highlighted in blue, we will require to specify the type of token_indexers under token). Otherwise you can omit any optional parameters from your configuration file.
This will be the final output used for the dataset_reader.
"dataset_reader":{
"type": "ptb_trees",
"token_indexers":{
"tokens": {
"type": "pretrained_transformer_mismatched",
"model_name": "bert-base-uncased"
}
}
}
- Defining the model
We will be using the same steps used to define the dataset_reader.
For this section, there are a few required parameters shown highlighted in the image below. The only exception is for Vocabulary as AllenNlp will handle it automatically. For an in-depth as to how AllenNLP handles the abstraction of the Vocabulary config parameters, you can refer to the documentation here
"model": {
"type": "constituency_parser",
"encoder": {
"type": "lstm",
"bidirectional": true,
"dropout": 0.2,
"hidden_size": 250,
"input_size": 768,
"num_layers": 4
},
"feedforward": {
"activations": "relu",
"hidden_dims": 2000,
"input_dim": 1000,
"num_layers": 1
},
"span_extractor": {
"type": "bidirectional_endpoint",
"input_dim": 1000
},
"text_field_embedder": {
"type": "basic",
"token_embedders": {
"tokens": {
"type": "pretrained_transformer_mismatched",
"model_name": "bert-base-uncased",
"train_parameters": false
}
}
}
}
- Include the training parameters
For the training parameters it is much more straightforward, specify the following parameters in the configuratin file as follows:
"train_data_path": "<insert file path of your training dataset>",
"validation_data_path": "<insert file path of your validation dataset>",
"trainer": {
"num_epochs": 100,
"optimizer": {
"type": "adam"
},
"patience": 5
},
"data_loader": {
"batch_size": 24,
"shuffle": true
}
Putting it together
{
"dataset_reader":{
"type": "ptb_trees",
"token_indexers":{
"tokens": {
"type": "pretrained_transformer_mismatched",
"model_name": "bert-base-uncased"
}
}
},
"model": {
"type": "constituency_parser",
"encoder": {
"type": "lstm",
"bidirectional": true,
"dropout": 0.2,
"hidden_size": 250,
"input_size": 768,
"num_layers": 4
},
"feedforward": {
"activations": "relu",
"hidden_dims": 2000,
"input_dim": 1000,
"num_layers": 1
},
"span_extractor": {
"type": "bidirectional_endpoint",
"input_dim": 1000
},
"text_field_embedder": {
"type": "basic",
"token_embedders": {
"tokens": {
"type": "pretrained_transformer_mismatched",
"model_name": "bert-base-uncased",
"train_parameters": false
}
}
}
},
"train_data_path": "<insert file path of your training dataset>",
"validation_data_path": "<insert file path of your validation dataset>",
"trainer": {
"num_epochs": 100,
"optimizer": {
"type": "adam"
},
"patience": 5
},
"data_loader": {
"batch_size": 24,
"shuffle": true
}
}
- Start Training
Once the configuration file has been defined, you can perform training by entering the following command in the Command Line Interface (CLI):
allennlp train <name of configuration file> -s <output directory>
Example:
allennlp train config_file.jsonnet -s my_first_model
AllenNlp will perform training based on the configuration file created and create a folder my_first_model where the outputs of the training will be saved.
- Evaluate Test Set
Evaluating the test set is straightforward, you can use the following command:
allennlp evaluate <saved_model.tar.gz> <test_data_file> --output-file <output_file>
Conclusion
In this post we’ve seen how to utilise AllenNLP to train a constituency parser in a much simpler way. By utilising the pre-defined classes in allennlp-models we can quickly get off the ground with training models or testing out new datasets. Hopefully this guys readers who are new to AllenNLP a better understanding of how to utilise one of the popular tools in the NLP world.